Encryption on dro.pm: a tale of misery and despair
Written on 2019-12-06
I run a site called dro.pm for fun. It creates short links and expires them after a while, which allows the links to be literally as short as dro.pm/k. Links can be "shortened links", text (pastebin-like), or a file.
Instead of emailing things to yourself, sending them through some chat service, or finding a USB stick, you can just go to this short domain and be done with it. You can write the short link on a blackboard or presentation and everyone can easily follow it. It also works on Linux, Windows, Android, whatever (no filesystem issues or having to exchange contact info with the/each recipient). It's useful to me and it doesn't cost me anything to make it available to others as well, so I'm happy for others to use it.
Encryption is something I have been thinking of for a while, and it was recently requested, so I started building it.
The requirements are simple: stream a file into a streaming encryption function and stream that to the web server. Something like this:
iv = os.urandom(16)
key = hashlib.scrypt(input("Password:"), salt=iv, p=2, N=2_000)
enc = Cipher(algorithms.AES(key), modes.GCM(iv))
sock = fsockopen("tls://dro.pm", 443)
sock.write('POST /api/upload HTTP/1.0\r\n')
sock.write('Content-Type: application/octet-stream\r\n')
length = filesize("my.file") + len(iv) + 16 # 16=GCM tag length
sock.write('Content-Length: {}\r\n'.format(length))
sock.write('\r\n')
sock.write(iv)
f = open('my.file', 'rb')
while chunk := f.read(1_000_000):
sock.write(enc.update(chunk))
sock.write(enc.finalize())
sock.close()Done. I skipped some implementation details like that I wouldn't write raw sockets, but for demonstrational purposes, this is it. This took me maybe half an hour, looking up whether Python can do argon2, what kind of object scrypt returns, which library supports authenticated encryption and what the default tag length is, how to stream into that encryption library, etc. Half an hour maybe. Add another half hour for making the code better and the implementation details that I skipped, maybe another half hour of testing, and we've got running code.
Enter JavaScript.
First, we need to read a file. That's the open() and read() calls above, so like 2 lines. The equivalent in JavaScript is this:
file = document.getElementById("myfileuploadelement").files[0];
var offset = 0;
var fr = new FileReader();
fr.onload = function() {
var data = new Uint8Array(fr.result);
console.log('Chunk contents:', data.toString());
offset += fileupload_chunksize;
fileupload_seek();
};
function fileupload_seek() {
if (offset >= file.size) {
// done
return;
}
var slice = file.slice(offset, offset + fileupload_chunksize);
fr.readAsArrayBuffer(slice);
}
fileupload_seek();Peanuts! This took longer than the complete example above, just to read a file. If someone else had written the code and I only needed to maintain it, it would take me forever to figure out what it does the first time I read it, especially when you then actually use the file's contents and the console.log() is replaced by other code.
So far, JavaScript is clunky and unmaintainable, and I only tried to read a file. This is where it goes from bad to worse. We need a few more things:
- Generate an IV (Python:
os.urandom(16)) - Use Argon2 or, failing that, scrypt to turn our password into a key (Python:
hashlib.scrypt(input("Password:"), salt=iv, p=2, N=2_000)) - Configure an authenticated encryption scheme (Python:
Cipher(algorithms.AES(key), modes.GCM(iv))) - Encrypt the data that we read from the file (Python:
enc.update(chunk)) - Send the encrypted data to the server (Python:
sock.write(data)) - Tell the server what we just uploaded so that the recipient can download it (filename and encryption parameters like the IV and which algorithm was used).
- Implement the JavaScript downloader that undoes the whole thing.
1. Generate an IV
Securely generated random data is the cornerstone of cryptography that has been missing from JavaScript for 19 years. Gmail was one of the first big web applications, and that was launched in 2004. Cryptography in the browser was not possible for another decade.
But it's 2020, we can do crypto.getRandomValues() now! This is the only reasonable line of JavaScript in this entire blog post:
crypto.getRandomValues(new Uint8Array(16));This Uint8Array object type is a bit clunky, but alright. This is 100% reasonable.
2. Use a secure, state-of-the-art KDF
Browser crypto hasn't been around for long, I think I've established that. Surely, when picking which algorithms to standardize and implement, they looked at what is an established standard that everyone would love to use today? Argon2 was the winner of the password hashing competition in 2015, picked for many reasons by many of the well-known names in the field. But perhaps that's a little too modern, I would cut them some slack and allow scrypt from 2009, which is a well-established. Or maybe at least bcrypt from 1999, which has a few advantages over the other oft-used PBKDF2 from 2000. That pretty much sums up all of the available choices, short of rolling your own.
drum roll
Of course they took PBKDF2.
Hah, okay, no memory-hardness for our users, and crackers get high speeds on GPUs while our users have to contend with CPU implementations.
For the implementation, you basically have to call importKey and deriveKey. The first one does nothing as far as I can tell and I haven't seen this in any other language, but the committee has decreed it shall be so. You also have to promise that you will only use your key for a certain purpose (like encryption or derivekey or wrapkey or I don't know), because that makes sense or something.
var enc = new TextEncoder();
var keythatiShot = await window.crypto.subtle.importKey("raw", enc.encode(key), {name: "PBKDF2"}, false, ["deriveKey"]);
var keythatisHot = await window.crypto.subtle.deriveKey({name: "PBKDF2", iterations: 1.5e6, hash: "SHA-256", salt: iv}, keythatiShot, { name: "AES-GCM", length: 256}, false, ["encrypt"]);
return keythatisHot;I would now remove the intermediate key material from memory, but of course JavaScript can't do secure memory erasure.
For me, it made a lot of sense that when I specify that it should do PBKDF2, I also need to specify the iteration count and perhaps other parameters. The importKey function happily accepts an iteration option, but ignores it completely. It should only be specified as an option for the deriveKey function.
Another issue is support. Internet Exploder doesn't support anything, but at the time of writing (the code), this would only be an issue for another month as Windows 7 support was running out. Edge, Microsoft's showpiece of a browser on the other hand, had "partial support":
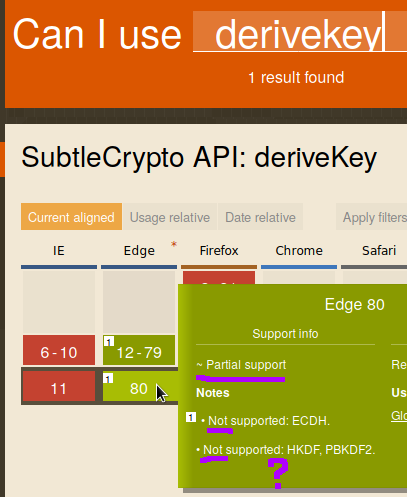
Which is a subtle way of saying "no support". To be clear, there are exactly three algorithms defined, and all three are said to be unsupported in Edge.
That looks weird, though. Surely one of those two lines is supposed to say "Supported" instead of "Not supported"? I asked a friend that owns a Windows machine (I won't mention any names) to open my test page. Turns out, TextEncoder is also not supported in Edge, but we can fix that with a polyfill of only 600KB. Next, Edge gave an error on line 105... which is a comment? After some trial and error, we got further and encountered a new error, this time on line 63... a blank line. Edge, please. To make a long story short, Edge really does not support any of the algorithms.
So I guess I'll have to drop support for all Microsoft browsers. That wouldn't generally be a big deal for my audience, but one of the key points of dro.pm is that you can use it to get files securely off of shitty systems like Windows (I have serious issues with that, short of setting up an unencrypted FTP server or installing custom software on the machine: by default, there is no scp or ssh, sftp/ftps, netcat+openssl pipes, nothing).
Maybe I'll have to provide a fallback and roll my own crypto (a puppy died when I wrote that sentence).
3. Configure an authenticated encryption scheme
await crypto.subtle.encrypt({name: "AES-GCM", iv: iv}, key, bytes);Did I lie when I said that the key derivation is the only reasonable line of JavaScript code? Because that looks entirely reasonable.
And it would be, for a demo implementation in high school. The careful reader will have noticed that this is not configuring an algorithm, this is encryption.
If you are on a phone, you may have a few hundred megabytes of RAM available. Given a bit of overhead and that you have to keep both the plaintext and encrypted forms in memory at the same time, a medium sized video would easily exhaust your available memory.
This is why basically no self-respecting software that handles files of more than a few megabytes keeps the entire file in memory. Video players, compression software (zip), encryption software, browsers that support downloading a file, none of them will try to keep your complete file in memory. What they do is reading it in chunks, processing the chunk, and writing the chunk to disk (or to the network, in our case).
So while we can encrypt files, and with a great and modern algorithm that does encryption and authentication in a single pass (AES-GCM, 2005), we cannot do it in chunks.
There are two options here:
- Either I limit uploads to a few megabytes for everyone, or
- I roll my own crypto (another puppy died when I wrote that sentence) and implement a makeshift CTR mode on top of AES-GCM.
I chose the latter (many puppies died in the making) because some crypto (made to the best of my professional ability) is presumably better than no crypto at all.
(Side note: the code shown in this post is not actually befitting of the title "made to the best of my professional ability": none of it ever made it even close to production and so hasn't been reviewed as carefully as I would otherwise have. It is all provided for demonstrational purposes.)
4. Encrypt the data chunks using our configured algorithm
Please refer back to the first piece of JavaScript code on this page. In the middle of that mess, there is a console.log(...view...). That has to call our encryption function instead, which does this:
await window.crypto.subtle.encrypt({name: "AES-GCM", iv: iv}, key, data);
incrementIV(iv);Where incrementIV(iv) is:
function incrementIV(iv) {
for (var i = 0; i < IVLEN; i++) {
if (iv[i] != 255) {
iv[i]++;
break;
}
iv[i] = 0;
}
}This is a custom scheme that I have never seen anywhere before, but this should be as safe as a standard AES-GCM implementation because the IV is unique for every call of the encryption. That's how it is designed to work: people want to reuse the key, so to make the encryption unique we use an IV that is not secret but unique. That's what this code does. The ugly part is that it adds an authentication tag to each chunk; that is overhead that is unavoidable without adding a second pass to the scheme (to do an HMAC over the data).
It honestly doesn't even look so bad, but abusing GCM in ways it wasn't meant for, implementing CTR mode by hand, having the overhead of an authentication tag with each chunk... this really isn't pretty.
5. Send the encrypted data to the server
Streaming data to the server seems relatively basic. As mentioned before, no self-respecting software ever loads an entire file into memory if it can be more than a few megabytes, surely browsers provide an API by which you can upload data to the server in chunks?
This exists for downloading, at least in a number of browsers. For uploading, however, this has been in the works since 2015, but it still isn't supported (let alone implemented in all major browsers).
So we have to hack something else together... After encrypting every chunk, we POST the encrypted result to the server with a sequence number, the server has to keep state and check the sequence number, and appends the chunks to a file.
6. Add some necessary metadata
It would be really shitty if the person downloading the encrypted file got a file named "unknown". No extension, no name, nothing. They couldn't open it by default, let alone have the correct name by default. Browsers solved this in the 90s: <input type=file> sends the filename (not path, for privacy reasons) to the server and the server can serve the download with a Content-Disposition: attachment; filename="my.mp3" header.
Similarly, you can do this in JavaScript:
document.getElementById("filefield").files[0].nameSo I happily implemented this and had almost moved onto the next step when I realized that, as always, with JavaScript you have to check browser support.
Wanna guess?
Safari on iOS and Firefox on Android don't support this. Among my target audience, both are major players. I guess I could do a fallback and implement a file extension field for those two browsers? Then the user has to, annoyingly, type mp3 or jpg or whatever into that field so that the recipient can open the file. Too bad that it has to include Safari on iOS, not Firefox on Linux or something where the person uploading presumably knows what a "file extension" is in the first place. But this is the best I can possibly do without having the user upload the file in plaintext to the server through an <input type=file> element, the very thing we were trying to replace.
We're so close now. Just decrypt on the client side and we're done. Boy, was I done with it at this point.
7. Download and revert the whole process
Remember how I mentioned that downloading in chunks is a thing? We can use that now. We can use the shiny new fetch API, read a chunk, slice it to the right length, authenticate that it hasn't been tampered with, decrypt the contents, and...
hold up, how do you write to a file? I've never seen a browser dialog created by JavaScript asking me where to store a file before it was generated, so where would the software write to? What I did see is things like Wire or Mega downloading it and showing a "save file" button after downloading, after which you put it in the right place. That sounds like a fine solution.
I actually got to this point. After adversity and despair, making it all this way, giving up on Internet Explorer, Edge, Safari on iOS, Firefox on Android, and a few so-far-unmentioned browsers like Opera Mini, but then I discovered that it just cannot be done. It turns out that browsers have limits of somewhere between 500 and 800 megabytes for blobs. Maybe this wouldn't be unacceptable by itself (even if it goes against the "it just works" philosophy of dro.pm: you click a button and it uploads; you go to the link and it downloads; no nonsense.), but put all the limitations together and I just cannot put this into production. Large file (>4GB) limitations were a thing of FAT32 and should really no longer be a thing.
But Mega does this, right? How do they do it? It seems they found some workaround for Chrome (a friend mentioned that stretches the limit to 2GB), but for Firefox and Safari it isn't possible. On Chrome you just have to have enough space on your OS disk, which would be a fairly reasonable limitation.
So this is where I gave up. Making a system that works only in Chrome, never mind.
I'm also not sure that entering strong passwords would be dro.pm users' forté: the service is meant to facilitate quick sharing, not require out of band communication of a 12 character random password. They could be put in the hash part of the URL, and while that gets the job done despite feeling wrong (secret tokens in a URL are a no-no), it would result in links like dro.pm/a#omgwhydidIbotherusingdropmanyway which aren't as easy to type over as the original short links which were the whole point of using dro.pm in the first place.
I've been trying to think of a fitting conclusion, but sadness is where it ends. I cannot just magically fix all browsers and have no hope that it will be fixed in the foreseeable future. It's 2020 and browser crypto remains a dark art.