Verifying Spotify's shuffle function
Written on 2016-01-14
Many, many people that use Spotify notice something weird about the shuffle function. It feels very... not random.
Out of a playlist of hundreds of songs, it picks the same artist three times in a row? And you heard two of those songs yesterday as well? What are the odds! Doing a search for just the word "shuffle" on Spotify's subreddit says enough, result after result is about the 'repetitive', 'broken' and 'shady' shuffle algorithm.

This begs the question, how do they screw up something so simple and why haven't they fixed it? Let's find out!
There are basically two ways to go about this: reverse engineering the binary or measuring observable behavior. I chose to do the latter and run the shuffle algorithm a while until a pattern appears.
Data gathering
Clicking the shuffle button and writing down which song got picked would be a very time consuming task, so I looked for a way to get the current song and control Spotify programmatically. I have to credit Arch Linux' wiki here, which is always a great source of information. The page told me I could go to the next song using this D-Bus command:
dbus-send --print-reply --dest=org.mpris.MediaPlayer2.spotify /org/mpris/MediaPlayer2 \
org.mpris.MediaPlayer2.Player.NextThis worked out of the box for me. Then getting the current song value, this time Arch Linux' forums gave me the solution:
dbus-send --print-reply --dest=org.mpris.MediaPlayer2.spotify /org/mpris/MediaPlayer2 \
org.freedesktop.DBus.Properties.Get string:'org.mpris.MediaPlayer2.Player' string:'Metadata'This D-Bus command prints some weird format:
variant array [
dict entry(
string "mpris:trackid"
variant string "spotify:track:7uVACIEJDMZUI7hCLwlpTM"
)
dict entry(
string "mpris:length"
variant uint64 253000000
)It looks like vaguely like JSON, but isn't. Turns out, the D-Bus developers thought it would be a great idea to invent their own, new format for communication. Hacking together a parser for the stuff I needed (source code on Github), I was now able to collect data: turn on shuffle, start playing the first song, and run the script to see which songs came next.
Using the data
So I had a shuffled list of songs that were played after each other. Okay. But how am I going to determine the 'randomness' of this? What if the next time you turn on shuffle, it plays half the songs in the same order, but it's shifted by 1 song? Or if they play them in reverse? There are almost infinitely many possibilities.
Thinking about this for a minute, I settled on running the script over and over again, picking only 20 random songs each time instead of going through the whole playlist, and checking how often each song got picked. For many possible schemes, this should show it clearly.
For those who care about the details, I wrote this bash one-liner (broken into multiple lines for readability):
sleep 2;
f=/path/file;
let i=0;
while :; do
if [ ! -f $f$i ]; then
./spotify-shuffle-stats.php -num20 > $f$i;
sleep 0.6;
xdotool click 1;
sleep 0.5;
else
echo skipping $i;
fi;
let i=$i+1;
doneI turned on shuffle, played the first song, then started this, and finally alt-tabbed back to spotify to put my mouse cursor on the play button next to the first song. This collects 20 shuffled songs and starts again from the top, which makes Spotify prepare a new shuffle queue.
Later I repeated this with picking only 4 random songs each time to see whether that made any difference, and then again in a shorter playlist to see how that worked out.
In the end, it played 25220 songs in a couple of hours.
Data analysis
Writing another quick script to combine and add up all plays in the files (see Github), I found the following: the least frequently played song was played 38 times, the most 74 times, and the remaining 340 songs somewhere in between. There seems to be a skew, some songs being played more than others (a uniform distribution would have a roughly equal amount for each song), but the skew was not really significant enough to give a definitive answer.
Looking at the data I got via D-Bus, songs have an 'AutoRating' as well. One theory was that Spotify looks at which songs you would like the most and then picks those more often. Graphing this gives the following:
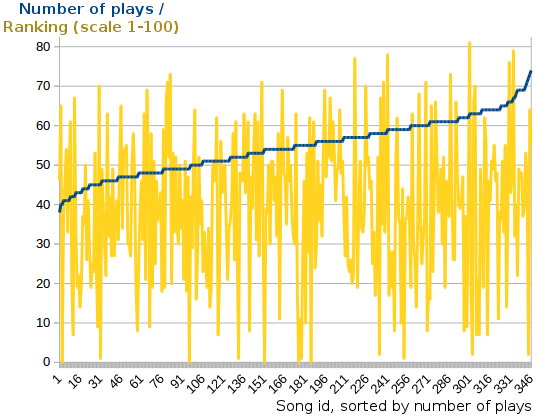
To the untrained eye this may look like a lot of garbage. The trained eye will however detect that it is indeed uncorrelated.
What is interesting is that the blue line is not just sloped, but also curves up and down near the ends. It isn't a major thing, but it was clearly there and I did not know whether it was supposed to behave like that or not.
I looked at some other song properties such as length (perhaps it favored short songs proportionally to give each an equal playing time?) and position of song in the playlist, but nothing had any correlation. The only thing I did not try was correlating with album or artist - I was going to, but then got an idea: how should the curve look if I simulate the whole thing?
Proving its randomness
What better way to prove something than by writing a piece of code to simulate what it should be doing, and seeing how the behaviors compare?
What Spotify should be doing is this:
- Take the list of songs to be shuffled.
- Pick a random song, place it in the 'shuffled' list and remove it from the list of songs to be shuffled.
- Go to step 2 until the list of songs to be shuffled is empty.
- Play the shuffled list from the top.
Simulating this, I wrote the following code:
$songs = []; // empty array
$tracks = 346; // amount of songs in my collection
// Fill the array with zeros
for ($i = 0; $i < $tracks; $i++) {
$songs[] = 0;
}
// In one of the tests, I played 18887 songs, so I
// simulated an equal number of plays.
for ($i = 0; $i < 18887; $i++) {
$songs[mt_rand(0, $tracks)]++; // Increment random index
}
// Output the results
for ($i = 0; $i < $tracks; $i++) {
echo "$songs[$i]\n";
}When graphed, this produced the following:
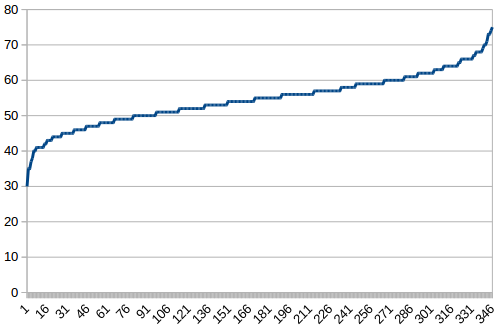
Looks familiar, doesn't it?
At this point I went in denial. Spotify's shuffle is really, provably random after all? What about all the "coincidences" that happened? This is weird.
Overlaying the two graphs, the results I generated earlier and the simulation output, really drives the point home.
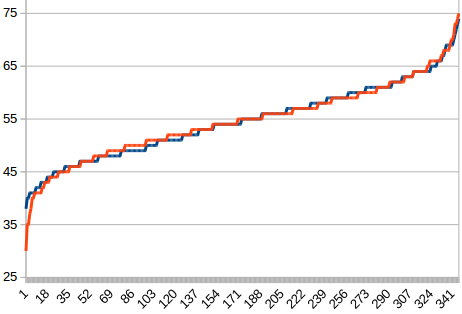
Conclusion
Humans are often credited with seeing patterns where there are none. Adding gambler's fallacy, the belief that the fifty-first toss should be tails if the first fifty tosses were heads, I think we can safely say this was one such instance.

Do it yourself!
You don't have to take my word for it, download the code and run it yourself: https://github.com/lgommans/spotify-shuffle
Graphs were made with LibreOffice Calc, sorting by number of plays. The PHP code should run on pretty much any GNU/Linux system where Spotify and D-Bus run on.